RISC-Vのベクトル命令一覧
全部で309命令+3命令だと思う(数え間違いがなければ...)
要素幅EEWとレジスタグループ幅LMULとはほぼ直交しているのでIntrinsicにすると1万命令くらいある。
実装的にはレジスタグループを考えなければ簡単な部類な命令が多い。 64bit整数の乗算/積和とか128bitの固定少数右シフトは回路面積が大きくなるのでuopに分解したほうがよさげ。
害悪ポイントはLMUL=8本でSEW=8bitの時のvrgatherei16.vv。スクラッチパッドのSRAMに書き出して読み出す実装ならレジスタの幅分だけのサイクル数がかかる。(vlen=128bitなら128cycle)
slideup/downは適当にレーン間の接続網(ringでもtorusでも)組んでやればいい気がする。
設定命令
vsetvli rd, rs1, vtypei vsetivli rd, uimm, vtypei vsetvl rd, rs1, rs2
Load Store命令
アライメント制約は要素サイズでありVLENではない。
vtypeのSEWは関係なく命令に直接エンコードされる。これによってvtypeを変える回数が減らせる。
Unit Stride 命令
vle8.v vd, (rs1), vm vle16.v vd, (rs1), vm vle32.v vd, (rs1), vm vle64.v vd, (rs1), vm vse8.v vs3, (rs1), vm vse16.v vs3, (rs1), vm vse32.v vs3, (rs1), vm vse64.v vs3, (rs1), vm
Strided 命令
Stride幅の制約は"整数"のバイト数(インデックスではない)なので0でも負でもいい。
vlse8.v vd, (rs1), rs2, vm vlse16.v vd, (rs1), rs2, vm vlse32.v vd, (rs1), rs2, vm vlse64.v vd, (rs1), rs2, vm vse8.v vs3, (rs1), rs2, vm vse16.v vs3, (rs1), rs2, vm vse32.v vs3, (rs1), rs2, vm vse64.v vs3, (rs1), rs2, vm
Indexed 命令
俗にいうGather、Scatter。vs2はバイト数を示す。
vluxei8.v vd, (rs1), vs2, vm vluxei16.v vd, (rs1), vs2, vm vluxei32.v vd, (rs1), vs2, vm vluxei64.v vd, (rs1), vs2, vm vloxei8.v vd, (rs1), vs2, vm vloxei16.v vd, (rs1), vs2, vm vloxei32.v vd, (rs1), vs2, vm vloxei64.v vd, (rs1), vs2, vm vsuxei8.v vs3, (rs1), vs2, vm vsuxei16.v vs3, (rs1), vs2, vm vsuxei32.v vs3, (rs1), vs2, vm vsuxei64.v vs3, (rs1), vs2, vm vsoxei8.v vs3, (rs1), vs2, vm vsoxei16.v vs3, (rs1), vs2, vm vsoxei32.v vs3, (rs1), vs2, vm vsoxei64.v vs3, (rs1), vs2, vm
順序あり(ordered)となし(unordered)がある。
Unit Stride Fault-Only-First Load 命令
先頭0番目の要素のみ例外をトラップさせる。それ以降で例外が発生した場合、ベクトル長vlを発生した箇所にする。
vle8ff.v vd, (rs1), vm vle16ff.v vd, (rs1), vm vle32ff.v vd, (rs1), vm vle64ff.v vd, (rs1), vm
Unit-Stride Segment 命令
SoA(Structure of Array)をAoS(Array of Structure)に変換する。
vlseg<nf>e<eew>.v vd, (rs1), vm vsseg<nf>e<eew>.v vs3, (rs1), vm
<nf>={1,2,3,4,5,6,7,8}
<eew>={8,16,32,64}
nf本のレジスタに書き込みが発生する。
Strided Segment命令
Stride幅付きのSegment命令
vlsseg<nf>e<eew>.v vd, (rs1), rs2, vm vssseg<nf>e<eew>.v vs3, (rs1), rs2, vm
<nf>={1,2,3,4,5,6,7,8}
<eew>={8,16,32,64}
Indexed Segment命令
Segment命令のGather、Scatter
vluxseg<nf>ei<eew>.v vd, (rs1), vs2, vm vloxseg<nf>ei<eew>.v vd, (rs1), vs2, vm vsuxseg<nf>ei<eew>.v vs3, (rs1), vs2, vm vsoxseg<nf>ei<eew>.v vs3, (rs1), vs2, vm
順序あり(ordered)となし(unordered)がある。
<nf>={1,2,3,4,5,6,7,8}
<eew>={8,16,32,64}
ロード命令はvd != vs2でないといけない(例外からの再開のため)
Whole Register命令
vlとかvtypeも関係なくベクトルレジスタをロードストアする。nfは一括で処理するレジスタ数
vl<nf>re<eew>.v vd, (rs1) vs<nf>r.v vs3, (rs1)
<nf>={1,2,3,4,5,6,7,8}
<eew>={8,16,32,64}
要素幅EEWは命令の動作に関係ない。ただのヒントらしい。
整数演算
加減算
vadd.vv vd, vs2, vs1, vm vadd.vx vd, vs2, rs1, vm vadd.vi vd, vs2, imm, vm vsub.vv vd, vs2, vs1, vm # vd[i] = vs2[i] - vs1[i] vsub.vx vd, vs2, rs1, vm # vd[i] = vs2[i] - x[rs1] vrsub.vv vd, vs2, rs1, vm # vd[i] = x[rs1] - vs2[i] vrsub.vx vd, vs2, imm, vm # vd[i] = imm - vs2[i]
拡幅加減算
等幅±等幅→倍幅
vwaddu.vv vd, vs2, vs1, vm vwaddu.vx vd, vs2, rs1, vm vwsubu.vv vd, vs2, vs1, vm vwsubu.vx vd, vs2, rs1, vm vwadd.vv vd, vs2, vs1, vm vwadd.vx vd, vs2, rs1, vm vwsub.vv vd, vs2, vs1, vm vwsub.vx vd, vs2, rs1, vm
倍幅±等幅→倍幅
vwaddu.wv vd, vs2, vs1, vm vwaddu.wx vd, vs2, rs1, vm vwsubu.wv vd, vs2, vs1, vm vwsubu.wx vd, vs2, rs1, vm vwadd.wv vd, vs2, vs1, vm vwadd.wx vd, vs2, rs1, vm vwsub.wv vd, vs2, vs1, vm vwsub.wx vd, vs2, rs1, vm
整数拡張
SEWはvdに適用される。
vs2の要素幅はSEWの1/2、1/4、1/8になる。
vzext.vf2 vd, vs2, vm vsext.vf2 vd, vs2, vm vzext.vf4 vd, vs2, vm vsext.vf4 vd, vs2, vm vzext.vf8 vd, vs2, vm vsext.vf8 vd, vs2, vm
キャリー(ボロー)付き加減算
マスクレジスタv0からキャリーを読み出し、vmadc vmsbcでレジスタにキャリーを入れる。
vadc.vvm vd, vs2, vs1, v0 vadc.vxm vd, vs2, rs1, v0 vadc.vim vd, vs2, imm, v0 vmadc.vvm vd, vs2, vs1, v0 vmadc.vxm vd, vs2, rs1, v0 vmadc.vim vd, vs2, imm, v0 vmadc.vv vd, vs2, vs1 vmadc.vx vd, vs2, rs1 vmadc.vi vd, vs2, imm
vsbc.vvm vd, vs2, vs1, v0 vsbc.vxm vd, vs2, rs1, v0 vmsbc.vvm vd, vs2, vs1, v0 vmsbc.vxm vd, vs2, rs1, v0 vmsbc.vv vd, vs2, vs1 vmsbc.vx vd, vs2, rs1
論理演算
vand.vv vd, vs2, vs1, vm vand.vx vd, vs2, rs1, vm vand.vi vd, vs2, imm, vm vor.vv vd, vs2, vs1, vm vor.vx vd, vs2, rs1, vm vor.vi vd, vs2, imm, vm vxor.vv vd, vs2, vs1, vm vxor.vx vd, vs2, rs1, vm vxor.vi vd, vs2, imm, vm
シフト演算
vsll.vv vd, vs2, vs1, vm vsll.vx vd, vs2, rs1, vm vsll.vi vd, vs2, uimm, vm vsrl.vv vd, vs2, vs1, vm vsrl.vx vd, vs2, rs1, vm vsrl.vi vd, vs2, uimm, vm vsra.vv vd, vs2, vs1, vm vsra.vx vd, vs2, rs1, vm vsra.vi vd, vs2, uimm, vm
狭幅シフト演算
倍幅>>等幅→等幅
vnsrl.wv vd, vs2, vs1, vm vnsrl.wx vd, vs2, rs1, vm vnsrl.wi vd, vs2, uimm, vm vnsra.wv vd, vs2, vs1, vm vnsra.wx vd, vs2, rs1, vm vnsra.wi vd, vs2, uimm, vm
比較演算
vmseq.vv vd, vs2, vs1, vm vmseq.vx vd, vs2, rs1, vm vmseq.vi vd, vs2, imm, vm vmsne.vv vd, vs2, vs1, vm vmsne.vx vd, vs2, rs1, vm vmsne.vi vd, vs2, imm, vm vmsltu.vv vd, vs2, vs1, vm vmsltu.vx vd, vs2, rs1, vm vmslt.vv vd, vs2, vs1, vm vmslt.vx vd, vs2, rs1, vm vmsleu.vv vd, vs2, vs1, vm vmsleu.vx vd, vs2, rs1, vm vmsleu.vi vd, vs2, imm, vm vmsle.vv vd, vs2, vs1, vm vmsle.vx vd, vs2, rs1, vm vmsle.vi vd, vs2, imm, vm vmsgtu.vx vd, vs2, rs1, vm vmsgtu.vi vd, vs2, imm, vm vmsgt.vx vd, vs2, rs1, vm vmsgt.vi vd, vs2, imm, vm
min/max
vminu.vv vd, vs2, vs1, vm vminu.vx vd, vs2, rs1, vm vmin.vv vd, vs2, vs1, vm vmin.vx vd, vs2, rs1, vm vmaxu.vv vd, vs2, vs1, vm vmaxu.vx vd, vs2, rs1, vm vmax.vv vd, vs2, vs1, vm vmax.vx vd, vs2, rs1, vm
乗算
vmul.vv vd, vs2, vs1, vm vmul.vx vd, vs2, rs1, vm vmulh.vv vd, vs2, vs1, vm vmulh.vx vd, vs2, rs1, vm vmulhu.vv vd, vs2, vs1, vm vmulhu.vx vd, vs2, rs1, vm vmulhsu.vv vd, vs2, vs1, vm vmulhsu.vx vd, vs2, rs1, vm
64bit乗算器実装したくないな...
除算/剰余算
vdivu.vv vd, vs2, vs1, vm vdivu.vx vd, vs2, rs1, vm vdiv.vv vd, vs2, vs1, vm vdiv.vx vd, vs2, rs1, vm vremu.vv vd, vs2, vs1, vm vremu.vx vd, vs2, rs1, vm vrem.vv vd, vs2, vs1, vm vrem.vx vd, vs2, rs1, vm
ソフトウェアでやるより命令があったほうがまし程度の意味合い。
拡幅乗算
等幅×等幅→倍幅
vwmul.vv vd, vs2, vs1, vm vwmul.vx vd, vs2, rs1, vm vwmulu.vv vd, vs2, vs1, vm vwmulu.vx vd, vs2, rs1, vm vwmulsu.vv vd, vs2, vs1, vm vwmulsu.vx vd, vs2, rs1, vm
積和演算
vmacc.vv vd, vs1, vs2, vm # vd[i] = +(vs1[i] * vs2[i]) + vd[i] vmacc.vx vd, rs1, vs2, vm # vd[i] = +(x[rs1] * vs2[i]) + vd[i] vnmsac.vv vd, vs1, vs2, vm # vd[i] = -(vs1[i] * vs2[i]) + vd[i] vnmsac.vx vd, rs1, vs2, vm # vd[i] = -(x[rs1] * vs2[i]) + vd[i] vmadd.vv vd, vs1, vs2, vm # vd[i] = (vs1[i] * vd[i]) + vs2[i] vmadd.vx vd, rs1, vs2, vm # vd[i] = (x[rs1] * vd[i]) + vs2[i] vnmsub.vv vd, vs1, vs2, vm # vd[i] = -(vs1[i] * vd[i]) + vs2[i] vnmsub.vx vd, rs1, vs2, vm # vd[i] = -(x[rs1] * vd[i]) + vs2[i]
積和演算は4オペランド命令ではなくvdを読み書きする
なんでか分からないけどアセンブリのオペランドの順番が違う
拡幅積和演算
(等幅×等幅)+倍幅→倍幅
vwmaccu.vv vd, vs1, vs2, vm # vd[i] = +(vs1[i] * vs2[i]) + vd[i] vwmaccu.vx vd, rs1, vs2, vm # vd[i] = +(x[rs1] * vs2[i]) + vd[i] vwmacc.vv vd, vs1, vs2, vm # vd[i] = +(vs1[i] * vs2[i]) + vd[i] vwmacc.vx vd, rs1, vs2, vm # vd[i] = +(x[rs1] * vs2[i]) + vd[i] vwmaccsu.vv vd, vs1, vs2, vm # vd[i] = +(signed(vs1[i]) * unsigned(vs2[i])) + vd[i] vwmaccsu.vx vd, rs1, vs2, vm # vd[i] = +(signed(x[rs1]) * unsigned(vs2[i])) + vd[i] vwmaccus.vx vd, rs1, vs2, vm # vd[i] = +(unsigned(x[rs1]) * signed(vs2[i])) + vd[i]
Merge命令
俗にいうConditional move。v0が条件選択。
vmerge.vvm vd, vs2, vs1, v0 vmerge.vxm vd, vs2, rs1, v0 vmerge.vim vd, vs2, imm, v0
レジスタ転送
マスクはないけどvlは関係あるのでリネームだけでは終わらない。
vmv.vv vd, vs1 vmv.vx vd, rs1 vmv.vi vd, imm
エイリアス命令だとtail-agnosticで値が壊れるため別命令として存在している
固定小数演算
vxsatで飽和するか決めれる。丸めは浮動小数レジスタのfrmを参照して動的丸めモードで行う。
固定少数とは言ってるけど便利命令程度。
飽和加減算
飽和したら最も近い表現可能な値にしてvxsatがセットされる。
vsaddu.vv vd, vs2, vs1, vm vsaddu.vx vd, vs2, rs1, vm vsaddu.vi vd, vs2, imm, vm vsadd.vv vd, vs2, vs1, vm vsadd.vx vd, vs2, rs1, vm vsadd.vi vd, vs2, imm, vm vssubu.vv vd, vs2, vs1, vm vssubu.vx vd, vs2, rs1, vm vssub.vv vd, vs2, vs1, vm vssub.vx vd, vs2, rs1, vm
平均加減算
加減算して1bitシフトしてxvrmに従って丸める。vasub vasubuのオーバーフローは無視される。
vaaddu.vv vd, vs2, vs1, vm vaaddu.vx vd, vs2, rs1, vm vaadd.vv vd, vs2, vs1, vm vaadd.vx vd, vs2, rs1, vm vasubu.vv vd, vs2, vs1, vm vasubu.vx vd, vs2, rs1, vm vasub.vv vd, vs2, vs1, vm vasub.vx vd, vs2, rs1, vm
丸めと飽和付きの分数乗算
乗算(単幅×単幅→倍幅)→シフト&丸め&飽和→単幅
vsmul.vv vd, vs2, vs1, vm vsmul.vx vd, vs2, rs1, vm
Scaling シフト
右シフトしてvxrmに従って丸める。
vssrl.vv vd, vs2, vs1, vm vssrl.vx vd, vs2, rs1, vm vssrl.vi vd, vs2, uimm, vm vssra.vv vd, vs2, vs1, vm vssra.vx vd, vs2, rs1, vm vssra.vi vd, vs2, uimm, vm
Narrowing Fixed-Point Clip
倍幅>>等幅→丸め→等幅
vnclipu.wv vd, vs2, vs1, vm vnclipu.wx vd, vs2, rs1, vm vnclipu.wi vd, vs2, uimm, vm vnclip.wv vd, vs2, vs1, vm vnclip.wx vd, vs2, rs1, vm vnclip.wi vd, vs2, uimm, vm
浮動小数演算
標準ではIEEE754-2008のfp32とfp64だけ
fp16はZvfh拡張
例外fflagsとかの特権命令まわりはF D拡張と同じ
丸めは浮動小数レジスタのfrmを参照して動的丸めモードで行う。
加減算
vfadd.vv vd, vs2, vs1, vm vfadd.vf vd, vs2, rs1, vm vfsub.vv vd, vs2, vs1, vm vfsub.vf vd, vs2, rs1, vm vfrsub.vf vd, vs2, rs1, vm
拡幅加減算
等幅±等幅→倍幅
vfwadd.vv vd、vs2、vs1、vm vfwadd.vf vd、vs2、rs1、vm vfwsub.vv vd、vs2、vs1、vm vfwsub.vf vd、vs2、rs1、vm vfwadd.wv vd、vs2、vs1、vm vfwadd.wf vd、vs2、rs1、vm vfwsub.wv vd、vs2、vs1、vm vfwsub.wf vd、vs2、rs1、vm
乗算除算
vfmul.vv vd, vs2, vs1, vm vfmul.vf vd, vs2, rs1, vm vfdiv.vv vd, vs2, vs1, vm vfdiv.vf vd, vs2, rs1, vm # vd[i] = vs2[i] / f[rs1] vfrdiv.vf vd, vs2, rs1, vm # vd[i] = f[rs1] / vs2[i]
拡幅乗算
等幅×等幅→倍幅
vfwmul.vv vd, vs2, vs1, vm vfwmul.vf vd, vs2, rs1, vm
積和演算
vfmacc.vv vd, vs1, vs2, vm # vd[i] = +(vs1[i] * vs2[i]) + vd[i] vfmacc.vf vd, rs1, vs2, vm # vd[i] = +(f[rs1] * vs2[i]) + vd[i] vfnmacc.vv vd, vs1, vs2, vm # vd[i] = -(vs1[i] * vs2[i]) - vd[i] vfnmacc.vf vd, rs1, vs2, vm # vd[i] = -(f[rs1] * vs2[i]) - vd[i] vfmsac.vv vd, vs1, vs2, vm # vd[i] = +(vs1[i] * vs2[i]) - vd[i] vfmsac.vf vd, rs1, vs2, vm # vd[i] = +(f[rs1] * vs2[i]) - vd[i] vfnmsac.vv vd, vs1, vs2, vm # vd[i] = -(vs1[i] * vs2[i]) + vd[i] vfnmsac.vf vd, rs1, vs2, vm # vd[i] = -(f[rs1] * vs2[i]) + vd[i] vfmadd.vv vd, vs1, vs2, vm # vd[i] = +(vs1[i] * vd[i]) + vs2[i] vfmadd.vf vd, rs1, vs2, vm # vd[i] = +(f[rs1] * vd[i]) + vs2[i] vfnmadd.vv vd, vs1, vs2, vm # vd[i] = -(vs1[i] * vd[i]) - vs2[i] vfnmadd.vf vd, rs1, vs2, vm # vd[i] = -(f[rs1] * vd[i]) - vs2[i] vfmsub.vv vd, vs1, vs2, vm # vd[i] = +(vs1[i] * vd[i]) - vs2[i] vfmsub.vf vd, rs1, vs2, vm # vd[i] = +(f[rs1] * vd[i]) - vs2[i] vfnmsub.vv vd, vs1, vs2, vm # vd[i] = -(vs1[i] * vd[i]) + vs2[i] vfnmsub.vf vd, rs1, vs2, vm # vd[i] = -(f[rs1] * vd[i]) + vs2[i]
4オペランドではなく3オペランド命令なのでvdを読み書きする
拡幅積和演算
±(等幅×等幅)±倍幅→倍幅
vfwmacc.vv vd, vs1, vs2, vm # vd[i] = +(vs1[i] * vs2[i]) + vd[i] vfwmacc.vf vd, rs1, vs2, vm # vd[i] = +(f[rs1] * vs2[i]) + vd[i] vfwnmacc.vv vd, vs1, vs2, vm # vd[i] = -(vs1[i] * vs2[i]) - vd[i] vfwnmacc.vf vd, rs1, vs2, vm # vd[i] = -(f[rs1] * vs2[i]) - vd[i] vfwmsac.vv vd, vs1, vs2, vm # vd[i] = +(vs1[i] * vs2[i]) - vd[i] vfwmsac.vf vd, rs1, vs2, vm # vd[i] = +(f[rs1] * vs2[i]) - vd[i] vfwnmsac.vv vd, vs1, vs2, vm # vd[i] = -(vs1[i] * vs2[i]) + vd[i] vfwnmsac.vf vd, rs1, vs2, vm # vd[i] = -(f[rs1] * vs2[i]) + vd[i]
平方根
vfsqrt.v vd, vs2, vm
近似平方根/逆数
近似は7bitでいいらしいのでテーブル引き
vfrsqrt7.v vd, vs2, vm vfrec7.v vd, vs2, vm
近似精度はニュートン・ラプソン法を0,1,2,3回実行すればbf16(e8m7) fp16(e5m10) fp32(e8m23) fp64(e11m52)になるかららしい
min/max
vfmin.vv vd, vs2, vs1, vm vfmin.vf vd, vs2, rs1, vm vfmax.vv vd, vs2, vs1, vm vfmax.vf vd, vs2, rs1, vm
符号注入
negateとかabsoluteにつかえる
vfsgnj.vv vd, vs2, vs1, vm vfsgnj.vf vd, vs2, rs1, vm vfsgnjn.vv vd, vs2, vs1, vm vfsgnjn.vf vd, vs2, rs1, vm vfsgnjx.vv vd, vs2, vs1, vm vfsgnjx.vf vd, vs2, rs1, vm
比較
vmfeq.vv vd, vs2, vs1, vm vmfeq.vf vd, vs2, rs1, vm vmfne.vv vd, vs2, vs1, vm vmfne.vf vd, vs2, rs1, vm vmflt.vv vd, vs2, vs1, vm vmflt.vf vd, vs2, rs1, vm vmfle.vv vd, vs2, vs1, vm vmfle.vf vd, vs2, rs1, vm vmfgt.vf vd, vs2, rs1, vm vmfge.vf vd, vs2, rs1, vm
分類分け
F D 拡張と同じ
vfclass.v vd, vs2, vm
Merge命令
浮動小数レジスタから読み出すCMOV (整数レジスタはvmerge.vxm)
vfmerge.vfm vd, vs2, rs1, v0
転送命令
浮動小数レジスタからの転送。命令エンコードがvfmerge.vfmと同じ。vm=1かつvs2=v0の時にvfmv.v.f
vfmv.v.f vd, rs1
型変換
vfcvt.xu.f.v vd, vs2, vm vfcvt.x.f.v vd, vs2, vm vfcvt.rtz.xu.f.v vd, vs2, vm vfcvt.rtz.x.f.v vd, vs2, vm vfcvt.f.xu.v vd, vs2, vm vfcvt.f.x.v vd, vs2, vm
拡幅型変換
単幅→倍幅
vfwcvt.xu.f.v vd, vs2, vm vfwcvt.x.f.v vd, vs2, vm vfwcvt.rtz.xu.f.v vd, vs2, vm vfwcvt.rtz.x.f.v vd, vs2, vm vfwcvt.f.xu.v vd, vs2, vm vfwcvt.f.x.v vd, vs2, vm vfwcvt.f.f.v vd, vs2, vm
狭幅型変換
倍幅→単幅
vfncvt.xu.f.w vd, vs2, vm vfncvt.x.f.w vd, vs2, vm vfncvt.rtz.xu.f.w vd, vs2, vm vfncvt.rtz.x.f.w vd, vs2, vm vfncvt.f.xu.w vd, vs2, vm vfncvt.f.x.w vd, vs2, vm vfncvt.f.f.w vd, vs2, vm vfncvt.rod.f.f.w vd, vs2, vm
縮約演算
vs2の全要素とvs1[0]との縮約をvd[0]に書き込む
単幅整数縮約
vredsum.vs vd, vs2, vs1, vm vredmaxu.vs vd, vs2, vs1, vm vredmax.vs vd, vs2, vs1, vm vredminu.vs vd, vs2, vs1, vm vredmin.vs vd, vs2, vs1, vm vredand.vs vd, vs2, vs1, vm vredor.vs vd, vs2, vs1, vm vredxor.vs vd, vs2, vs1, vm
拡幅整数縮約
sum(単幅)→倍幅
vwredsumu.vs vd, vs2, vs1, vm vwredsum.vs vd, vs2, vs1, vm
浮動小数縮約
vfredosum.vs vd, vs2, vs1, vm vfredusum.vs vd, vs2, vs1, vm vfredmax.vs vd, vs2, vs1, vm vfredmin.vs vd, vs2, vs1, vm
演算過程は有限精度なため、順序ありorderedとなしunordered命令がある。
拡幅浮動小数縮約
sum(単幅)→倍幅
vfwredosum.vs vd, vs2, vs1, vm vfwredusum.vs vd, vs2, vs1, vm
マスク演算
マスク論理演算
vmand.mm vd, vs2, vs1 vmnand.mm vd, vs2, vs1 vmandn.mm vd, vs2, vs1 vmxor.mm vd, vs2, vs1 vmor.mm vd, vs2, vs1 vmnor.mm vd, vs2, vs1 vmorn.mm vd, vs2, vs1 vmxnor.mm vd, vs2, vs1
count population
マスクが立ってるエレメント数を数える
vcpop.m rd, vs2, vm
ベクトルレジスタに書き込みを行わず、整数レジスタに転送する。再開はできるわけないのでvstartは常に0
find-first-set mask bit
マスクに1が立っている最初のエレメントの位置を返す
vfirst.m rd, vs2, vm
ベクトルレジスタに書き込みを行わず、整数レジスタに転送する。再開はできるわけないのでvstartは常に0
set-before-first/set-including-first/set-only-first
マスクに1が立っている最初のエレメントの位置を探して{以前, 以後, その場所}に1を立てる
vmsbf.m vd, vs2, vm vmsif.m vd, vs2, vm vmsof.m vd, vs2, vm
文字列比較(ヌル文字)&コピーとかに使う。再開はできるわけないのでvstartは常に0
Iota命令
自分の位置より前のマスクの有効な数を数える
viota.m vd, vs2, vm
再開はできるわけないのでvstartは常に0
Element Index
エレメントの場所
vid.v vd, vm
並べ替え命令
スカラ転送命令
マスクとvlに関係なく実行される。vm=0は予約命令。
整数レジスタとベクトルレジスタの0番目の要素の転送
vmv.x.s rd, vs2 vmv.s.x vd, rs1
浮動小数レジスタとベクトルレジスタの0番目の要素の転送。
vfmv.f.s rd, vs2 vfmv.s.f vd, rs1
スライド命令
vslideup.vx vd, vs2, rs1, vm vslideup.vi vd, vs2, uimm, vm vslidedown.vx vd, vs2, rs1, vm vslidedown.vi vd, vs2, uimm, vm
再開を実現するためにvd != vs2でなくてはいけない
Slide1up/down
整数レジスタor浮動小数レジスタから読み込んで1個ずつずらす
vslide1up.vx vd, vs2, rs1, vm vfslide1up.vf vd, vs2, rs1, vm vslide1down.vx vd, vs2, rs1, vm vfslide1down.vf vd, vs2, rs1, vm
Gather命令
vd[i] = (vs1[i] >= VLMAX) ? 0 : vs2[vs1[i]]
vrgather.vv vd, vs2、vs1, vm vrgatherei16.vv vd, vs2, vs1, vm
SEW=8のときはvs1が0~255までしか指定できないのでvrgatheri16.vvはレジスタグループで64Kまで指定できるようにしている
再開を実現するためにvd != vs2でなくてはいけない
vrgather.vx vd, vs2, rs1, vm vrgather.vi vd, vs2, uimm, vm
ただのブロードキャスト。再開を実現するためにvd != vs2でなくてはいけない
圧縮命令
vs1が有効な値(非ゼロ)の位置のvs2の値を先頭から詰める。
vcompress.vm vd, vs2, vs1
途中で再開が難しいため、vstart != 0なら不正命令例外。マスク命令vm=0は存在せず、予約済み。
ベクトルレジスタ全体転送命令
レジスタグループにして全転送。マスクもtailも関係ないので、リネーミングだけで済ませても良い。
vmv<nr>r.v vd, vs2
<nr>={1,2,4,8}
RISC-Vの浮動小数と整数レジスタの分離ができない命令
| 命令 | レジスタ(R→W) f:浮動小数レジスタ x:整数レジスタ |
|---|---|
fld flw |
x→f |
fsd fsw |
x,f→ |
feq.d flt.d fle.d |
f,f→x |
fclass.d |
f→x |
fcvt.w.d fcvt.l.d |
f→x |
fcvt.d.w fcvt.d.l |
x→f |
fmv.d.x |
x→f |
fmv.x.d |
f→x |
浮動小数レジスタには整数表現が乗らないので、「IEEE754を表現できる」ことが必要条件である。そのため、計算が正確なら、非正規化数をそのまま表現せず、簡単な表現で実装しても良い。
RV64GBでOp fusionできそうな命令列
最近RV64GBの命令列を見ていてOp fusionできそうな命令が結構あったので、抜き出してみた。
rs1をrs2の整数倍になるように切り捨て
div rd, rs1, rs2 mul rd, rd, rs2
実装は以下のようになりレイテンシをmulからsubへ置き換えることができる
rem rd, rs1, rs2 sub rd, rs1, rd
比較
rs1 == -imm
immは-1か-2が多い
addi rd, rs1, imm seqz rd, rd
rs1 != -imm
addi rd, rs1, imm snez rd, rd
(rs1&rs2) == 0
and rd, rs1, rs2 seqz rd, rd
(rs1^rs2) == 0
xor rd, rs1, rs2 seqz rd, rd
(rs1|rs2) == 0
or rd, rs1, rs2 seqz rd, rd
rs1 >= imm
slti rd, rs1, imm not rd, rd
即値より上という命令はないのでよく出てくる
アドレス計算
&rs2[rs1+imm]
addi rd, rs1, imm sh2add rd, rd, rs2
&(rs2[rs1])+imm
sh2add rd, rs1, rs2 addi rd, rd, imm
rs2[rs1]
sh3add rd, rs1, rs2 ld rd, 0(rd)
std::distance(rs1, rd)
2の累乗の大きさの要素を持つiteratorの距離を、アドレスから計算する
sub rd, rd, rs1 srai rd, rd, imm
浮動小数の絶対値との加減算
fabs.d rd, rd fsub.d rd, rd, rs1
fsub.d rd, rs1, rs2 fabs.d rd, rd
符号ビットを0にするだけなので実装が簡単
ハードウェア的に簡単に実装できないor構造の大規模変更が必要なもの
浮動小数の+0との比較
浮動小数レジスタと整数レジスタに書き戻しが必要
fmv.d.x ft0, zero flt.d rd,rs1,ft0
RISC-Vのゼロレジスタが必要な疑似命令
| 疑似命令 | 展開 |
|---|---|
| nop | addi zero, zero, 0 |
| li rd, imm | addi rd, zero, imm |
| neg rd, rs | sub rd, zero, rs |
| negw rd, rs | subw rd, zero, rs |
| snez rd, rs | sltu rd, zero, rs |
| sltz rd, rs1 | slt rd, rs, zero |
| sgtz rd, rs1 | slt rd, zero, rs |
| beqz rs offset | beq rs, zero, offset |
| bnez rs offset | bne rs, zero, offset |
| bgez rs offset | bge rs, zero, offset |
| blez rs offset | bge zero, rs, offset |
| bltz rs offset | blt rs, zero, offset |
| bgtz rs offset | blt zero, rs offset |
| j offset | jal zero, offset |
| ret | jalr zero, x1, 0 |
| csrr rd, csr | csrrs rd, csr, zero |
| csrw csr, rs | csrrs zero, csr, rs |
「ゼロ比較」と「何もしない」ことに使うのが多いようだ
RV64の32bit用命令について
RV64命令セットの32bit用命令
RV64命令セットでは通常のadd命令では64bit幅で計算を行うが、sraw addw add.uwのような32bit用の命令が定義されている。
呼び出し規約曰く
The C types char and unsigned char are 8-bit unsigned integers and are zero-extended when stored in a RISC-V integer register. unsigned short is a 16-bit unsigned integer and is zeroextended when stored in a RISC-V integer register. signed char is an 8-bit signed integer and is sign-extended when stored in a RISC-V integer register, i.e. bits (XLEN-1)..7 are all equal. short is a 16-bit signed integer and is sign-extended when stored in a register. In RV64, 32-bit types, such as int, are stored in integer registers as proper sign extensions of their 32-bit values; that is, bits 63..31 are all equal. This restriction holds even for unsigned 32-bit types.
とのことで、32bitで0x8765'4321という値は、レジスタ内では「符号に関わらず」符号拡張され0xFFFF'FFFF'8765'4321という値で格納される。
なお、16bitと8bit整数については符号ありであれば符号拡張、符号なしであれば0埋めで格納される。
The RISC-V Instruction Set Manual曰く比較命令には手を加える必要がなく
- u32⇔i32
の変換がノーコストになるのが利点らしい。
The compiler and calling convention maintain an invariant that all 32-bit values are held in a sign-extended format in 64-bit registers. Even 32-bit unsigned integers extend bit 31 into bits 63 through 32. Consequently, conversion between unsigned and signed 32-bit integers is a no-op, as is conversion from a signed 32-bit integer to a signed 64-bit integer. Existing 64-bit wide SLTU and unsigned branch compares still operate correctly on unsigned 32-bit integers under this invariant. Similarly, existing 64-bit wide logical operations on 32-bit sign-extended integers preserve the sign-extension property. A few new instructions (ADD[I]W/SUBW/SxxW) are required for addition and shifts to ensure reasonable performance for 32-bit values.
呼び出し規約のために修正が必要な命令
sraw, sllw
左シフトすると"bits 63..31 are all equal."という状況が崩れるため、上位32bitを同じにする必要がある。
addw, subw
オーバーフロー時に上位32bitが崩れるため、左シフトと同様。
srlw
符号なし32bitの0x8765'4321を4bit右シフトした値は0x0876'5432である。
しかしレジスタ内では0xFFFF'FFFF'8765'4321と表現されているため、SRL命令では0xF876'5432となり正しく32bitの右シフトを実行できない。
そのためSRLW命令では下記のように上位32bitを無視して実行することにより、正しい32bit右シフトを実行する。
x[rd] = sext(x[rs1][31:0] >> x[rs2][4:0])
add.uw, sh1add.uw
64bit整数と符号あり32bitの加算はADD命令で正常に計算できる。
しかし64bit整数と符号なし32bitとの加算では、上位32bitが(なぜか)符号拡張されているため0x1(u64) + 0x8765'4321(u32)は0x00...001 + 0xFF...FF'8765'4321と計算されてしまう。
そのため、下記のように上位32bitをゼロ拡張する必要がある。
x[rd] = {32'0, x[rs1][31:0]} + x[rs2]
雑感
変な規約の理由が、C言語の整数演算がint or unsigned intに昇格されることが多いからくらいしか思いつかない。
正直、i32の正の範囲である[0, 2^31-1]に収まらなければ、両者の変換はオーバーフローorアンダーフローで範囲チェックを入れる必要がある。正常な範囲では符号の有無でビット表現は変わらないので、ノーコスト変換可能である。
加えて、u32⇒i64 or u64の変換にコストがかかり、必要なzext.w命令はzba拡張で後付けである。RV64Iには含まれていないため、下記のようなシフト命令で代用する必要がある。
slli t0, t0, 32 srli t0, t0, 32
変換コストはかなり気を付けながらコーディングしなければ発生するので、おとなしく符号拡張(ゼロ拡張)命令を実装して各アーキテクチャがop-fusionした方がよかった気がする。
Milk-V Jupiter(SpacemiT K1)のコアの性能評価
この記事はなに?
Milk-V Jupiterを買って半年ほど使い、どうも性能がおかしいときがある。
なので色々とベンチマークプログラムを組みリバースエンジニアリングし、ボトルネックの調査を行った。
SpacemiT K1
Milk-V JupiterにはSpacemiT社のK1というSoCが搭載されていて、メインのCPUはX60というアーキテクチャらしい。
理論性能
- 倍精度 12.8 GFLOPS = 4(256b vector)×2 FMA×1.6 GHz
- 単精度 25.6 GFLOPS = 8(256b vector)×2 FMA×1.6 GHz
実行性能
OpenBLASで倍精度行列積(dgemm)の実行性能(横軸:行数(列数)、縦軸:GFLOPS)
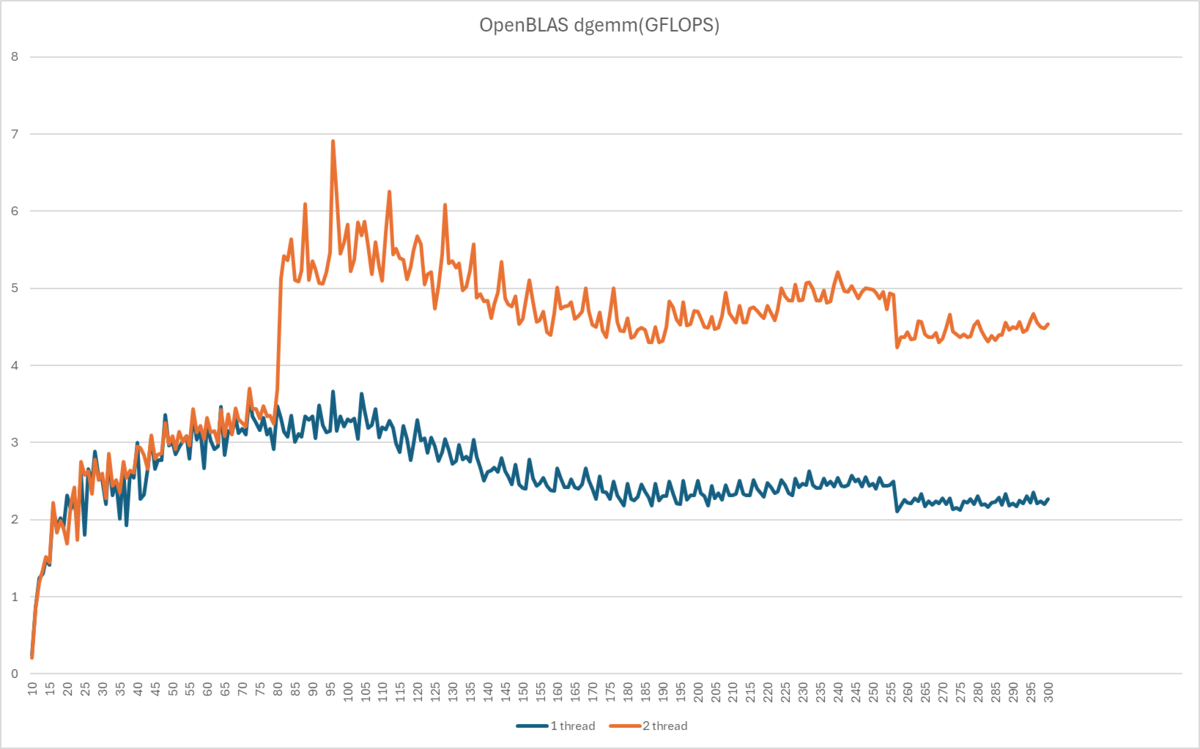
実行効率が28.6 %であまりにも低い。(同じdual-issue&in-orderなCortex-A53で55.3 %) あと、行列サイズが大きくなると実行効率が落ちるのも何かがおかしい。
対応拡張命令
RISC-Vは基本命令は最小構成過ぎるので、拡張命令によって必要な機能をサポートする。 とりあえずLinuxのデバイスツリーから読み取れるのは
- "i" 基本命令
- "m"乗算拡張
- "a" アトミック拡張
- "f" 単精度浮動小数
- "d" 倍精度浮動小数
- "c"16bit圧縮命令
- "v"ベクトル命令(このCPUが欲しかった理由)
- "zicbom" キャッシュ操作(仕様が古いのかIllegal Instructionで動かない)
- "zicbop" キャッシュプリフェッチ
- "zicboz" キャッシュゼロ埋め
- "zicntr" ユーザーレベルカウンタ&タイマー(
timeしか実装されてない) - "zicond" conditional move命令(RISC-likeなcmov)
- "zicsr" CSR(Control and Status Register)読み書き命令
- "zifencei" 命令キャッシュ・パイプラインの同期命令
- "zihintpause" パフォーマンス制限のヒント
- "zihpm" パフォーマンスカウンタ
- "zfh" 半精度浮動小数
- "zba","zbb", "zbc", "zbs" ビット操作命令(B拡張)が4つに分割された姿(明らかにビット操作ではない命令もある)
- "zkt" 命令の実行時間がレジスタの中身に依存しない
- "zvfh" 半精度浮動小数ベクトル命令
- "zvkt" zktのベクトル命令版
- "sscofpmf" パフォーマンスカウンタのオーバーフロー割り込み
- "sstc" Supervisor-modeのタイマー割り込み
- "svinval" TLB制御命令
- "svnapot" PMP(Physical Memory Protection)のアドレス指定法
- "svpbmt" メモリ属性(PMA)をページテーブルからオーバーライドできる
である。
一部動かない命令があるが、SpacemiTが仕様バージョンすら公開されていないので原因はよく分からない。基本的にコンパイルするときは、rv64gcv_zba_zbb_zbs_zicondだけ覚えておけばいい。
X60コア
以下各種ベンチマークプログラムから推測した性能。
スカラー命令
RV64I
| OP | レイテンシ | CPI |
|---|---|---|
| xor | 1 | 0.5 (2命令同時実行) |
| add | 1 | 0.5 (2命令同時実行) |
| sll | 1 | 0.5 (2命令同時実行) |
| slt | 1 | 0.5 (2命令同時実行) |
| ld | 2 | 1 |
| sd | ー | 1 |
| sw | ー | 1 |
RV64M
| OP | レイテンシ | CPI |
|---|---|---|
| mul | 5 | 3 |
| mulh | 6 | 4 |
| mulhsu | 6 | 4 |
| mulhu | 6 | 4 |
| mulw | 3 | 1 |
RV64F
| OP | レイテンシ | CPI |
|---|---|---|
| fmax.s | 3 | 0.5 |
| fadd.s | 3 | 0.5 |
| fmul.s | 3 | 0.5 |
| fmadd.s | 4 | 1 |
| flw | >2 | 1.25(4命令に1stall?) |
| fsw | ー | 1.5(2命令に1stall?) |
RV64D
| OP | レイテンシ | CPI |
|---|---|---|
| fmax.d | 3 | 0.5 |
| fadd.d | 3 | 0.5 |
| fmul.d | 4 | 0.5 |
| fmadd.d | 5 | 1 |
| fld | >2 | 1.25 |
| fsd | ? | 1.5 |
ベクトル命令
- レジスタ幅256bit
- 演算器256bit/cycle
| OP | レイテンシ | CPI |
|---|---|---|
| vsetvl(ベクトル長設定) | 3 cycle | 3 |
| vfadd.vv | 3 cycle | 1 |
| vfmul.vv | 4 cycle | 1 |
| vfmacc.vv | 5 cycle | 1 |
レジスタグループ化(8本)
| OP | レイテンシ | CPI |
|---|---|---|
| vfadd.vv | 8 cycle | 8 |
| vfmul.vv | 8 cycle | 8 |
| vfmacc.vv | 8 cycle | 8 |
レジスタグループ化しない場合、vfmacc.vvを8回実行すると完了までに(8+5cycle)かかるが、8本でグループ化すると8 cycleで完了するのでお得に見える。
残念ながら、パイプラインが詰まり同時命令実行ができないので、全然得じゃない。
同時命令実行
| OP | スカラー | ロードストア | ベクトル |
|---|---|---|---|
| スカラー | 〇(fmaccは×) | 〇 | 〇(レジスタグループ化した場合×) |
| ロードストア | - | × | 〇(レジスタグループ化した場合×) |
| ベクトル | - | - | × |
メモリ階層
- L1 d-cache 32KiB(64B×128 blocks×4 ways)
- L1 i-cache 32KiB(64B×128 blocks×4 ways)
- L2 cache 512KiB(64B×512 blocks×16 ways)

メモリアクセスレイテンシ
- L1 hit 2cycle
- L2 hit 34cycle程度
- DRAM 90cycle程度
TLB
- L1TLB 16エントリ(ペナルティなし)
- L2TLB 512エントリ?(+9cycle)
なのでL1 cahe hitでL2TLB hitなら11cycleでld命令が完了する。
メモリ帯域

・・・・・・・・・・・・はい。原因です。L1-L2間の帯域が細すぎ
- L1 d-cache 128bit/cycleでアクセス可能
- L2 cache 32bit/cycle???
- LPDDR4X デュアルチャネルだろうがなんだろうがL2が遅すぎて関係ない
今回書いたプログラムおいておきます。
Milk-V Jupiterが届いた
Milk-V Jupiterの16GB版が(やっと)届いたので色々試してみた。

準備
OS
起動にはMicroSDにBalenaEtcherなどでOSを焼く必要がある。OSイメージはUbuntu 23.10とBianbu OSというUbuntuベースのオリジナルが提供されている。
私はUbuntu23.10を入れた。
電源
Milk-V JupiterはATX電源、ACアダプタ(2.5mmジャック)、USB PDの3種類の給電方法が用意されている。PoEは追加ボードが必要なのだが、入手手段がないので現状は利用できない。
とりあえず手元にあったACアダプタで給電することにした。
起動後の確認
lscpu
Architecture: riscv64 Byte Order: Little Endian CPU(s): 8 On-line CPU(s) list: 0-7 Model name: Spacemit(R) X60 Thread(s) per core: 1 Core(s) per socket: 8 Socket(s): 1 CPU(s) scaling MHz: 100% CPU max MHz: 1800.0000 CPU min MHz: 614.4000 Caches (sum of all): L1d: 256 KiB (8 instances) L1i: 256 KiB (8 instances) L2: 1 MiB (2 instances)
lstopo

M.2
Optane M10 16GBを挿してみたが認識されない。M.2→SATA6ポート変換基板は認識されるので、相性があるのかもしれない。
有線LAN
SoC内蔵で1GbEが2ポートついているがMACアドレスが存在しないのでFE:FE:FE:x:x:xというランダム生成されたMACアドレスが起動毎に割り当てられる。起動のたびに変わるのは色々と不便なのでにnetplan等で固定する。加えてチェックサムオフローディングがないので異様にCPU負荷が高い。
ベンチマーク(coremark)
ちゃんとコンパイルオプションをつければCortex-A55より速い。genericなRV64GCだけだとCortex-A55並みな性能になった。
コンパイラだが、gccはRVVの対応が遅く自動ベクトル化が期待できない。一方Clangは、自動ベクトル化もIntrinsic対応もよい感じだが、自動ベクトル化を含めてもgccの方が最適化されていて速い。
gcc(RV64GCのみ)
2K performance run parameters for coremark.
CoreMark Size : 666
Total ticks : 17226
Total time (secs): 17.226000
Iterations/Sec : 6385.696041
Iterations : 110000
Compiler version : GCC13.2.0
Compiler flags : -O2 -march=rv64gc -DPERFORMANCE_RUN=1 -lrt
Memory location : Please put data memory location here
(e.g. code in flash, data on heap etc)
seedcrc : 0xe9f5
[0]crclist : 0xe714
[0]crcmatrix : 0x1fd7
[0]crcstate : 0x8e3a
[0]crcfinal : 0x33ff
Correct operation validated. See README.md for run and reporting rules.
CoreMark 1.0 : 6385.696041 / GCC13.2.0 -O2 -march=rv64gc -DPERFORMANCE_RUN=1 -lrt / Heap
gcc(最適化オプションあり)
2K performance run parameters for coremark.
CoreMark Size : 666
Total ticks : 13977
Total time (secs): 13.977000
Iterations/Sec : 7870.072262
Iterations : 110000
Compiler version : GCC13.2.0
Compiler flags : -O2 -march=rv64gcv_zba_zbb_zbs_zbc_zicond_zvl256b -misa-spec=2.2 -funroll-all-loops -finline-functions -DPERFORMANCE_RUN=1 -lrt
Memory location : Please put data memory location here
(e.g. code in flash, data on heap etc)
seedcrc : 0xe9f5
[0]crclist : 0xe714
[0]crcmatrix : 0x1fd7
[0]crcstate : 0x8e3a
[0]crcfinal : 0x33ff
Correct operation validated. See README.md for run and reporting rules.
CoreMark 1.0 : 7870.072262 / GCC13.2.0 -O2 -march=rv64gcv_zba_zbb_zbs_zbc_zicond_zvl256b -misa-spec=2.2 -funroll-all-loops -finline-functions -DPERFORMANCE_RUN=1 -lrt / Heap
clang(最適化オプションあり)
2K performance run parameters for coremark.
CoreMark Size : 666
Total ticks : 12042
Total time (secs): 12.042000
Iterations/Sec : 4982.561036
Iterations : 60000
Compiler version : Ubuntu Clang 17.0.2 (1~exp1ubuntu2.1-bb1 56277be0dfab53becb87b035a858df5a10632457)
Compiler flags : -O2 -march=rv64gcv_zba_zbb_zbs_zbc_zicond1p0_zvl256b -funroll-loops -finline-functions -menable-experimental-extensions -DPERFORMANCE_RUN=1 -lrt
Memory location : Please put data memory location here
(e.g. code in flash, data on heap etc)
seedcrc : 0xe9f5
[0]crclist : 0xe714
[0]crcmatrix : 0x1fd7
[0]crcstate : 0x8e3a
[0]crcfinal : 0xbd59
Correct operation validated. See README.md for run and reporting rules.
CoreMark 1.0 : 4982.561036 / Ubuntu Clang 17.0.2 (1~exp1ubuntu2.1-bb1 56277be0dfab53becb87b035a858df5a10632457) -O2 -march=rv64gcv_zba_zbb_zbs_zbc_zicond1p0_zvl256b -funroll-loops -finline-functions -menable-experimental-extensions -DPERFORMANCE_RUN=1 -lrt / Heap